Machine learning for equipment maintenance
Background
I undertook a predictive maintenance project using a dataset comprising sensor data from industrial machinery. The goal was to predict component failures, mitigating risks associated with machine downtime and maintenance costs. The dataset contained 307,751 records, representing operational data from 421 machines over 731 days.
Problem Faced
In this project, I addressed the challenge of predicting equipment failures in industrial machinery using a dataset with 307,751 records. The key difficulty was the data's highly imbalanced nature, marked by a minuscule 0.14% failure rate, posing risks of model bias. My task was to develop a predictive maintenance (PM) model that could accurately forecast failures, thus avoiding costly over-maintenance and the risks associated with under-maintenance.
The project demanded a strategic approach to machinery maintenance, traditionally categorized into over-maintenance, under-maintenance, and timely maintenance. The aim was to strike a balance between these scenarios, moving beyond standard manufacturer recommendations to tailor maintenance schedules based on actual operational data. The model needed to predict failures within a 90-day window, aligning with the machines' diverse operational conditions.
An essential aspect of the project was its economic implications. The goal was to reduce the average maintenance cost per machine, currently estimated at about $28,000. This involved not just building a predictive model but also ensuring it led to significant cost savings and operational efficiency, presenting a complex intersection of machine learning, engineering insights, and economic analysis.

Table #1: Maintenance Scenarios and Its Associated Costs.
Actions (see below for source code)
Frameworks and Software Packages Used:
Python and Jupyter Notebook: For scripting and data analysis.
Pandas and NumPy: For data manipulation and numerical calculations.
Scikit-Learn: For machine learning tasks like data splitting and model evaluation.
XGBoost: Used for handling large, complex datasets effectively.
Imbalanced-Learn (SMOTE): Addressed data imbalance by synthetically balancing the dataset.
Challenges Encountered:
Data Imbalance: Overcoming the skewed dataset to avoid model bias.
Feature Engineering: Extracting meaningful features from raw sensor data, creating 21-day running summaries for each sensor (S5 to S19) and calculating their mean, median, max, min, and change.
Model Interpretability: Ensuring the model's decisions were explainable within an industrial context.
Economic Impact Assessment: Translating model results into tangible economic implications for informed decision-making.
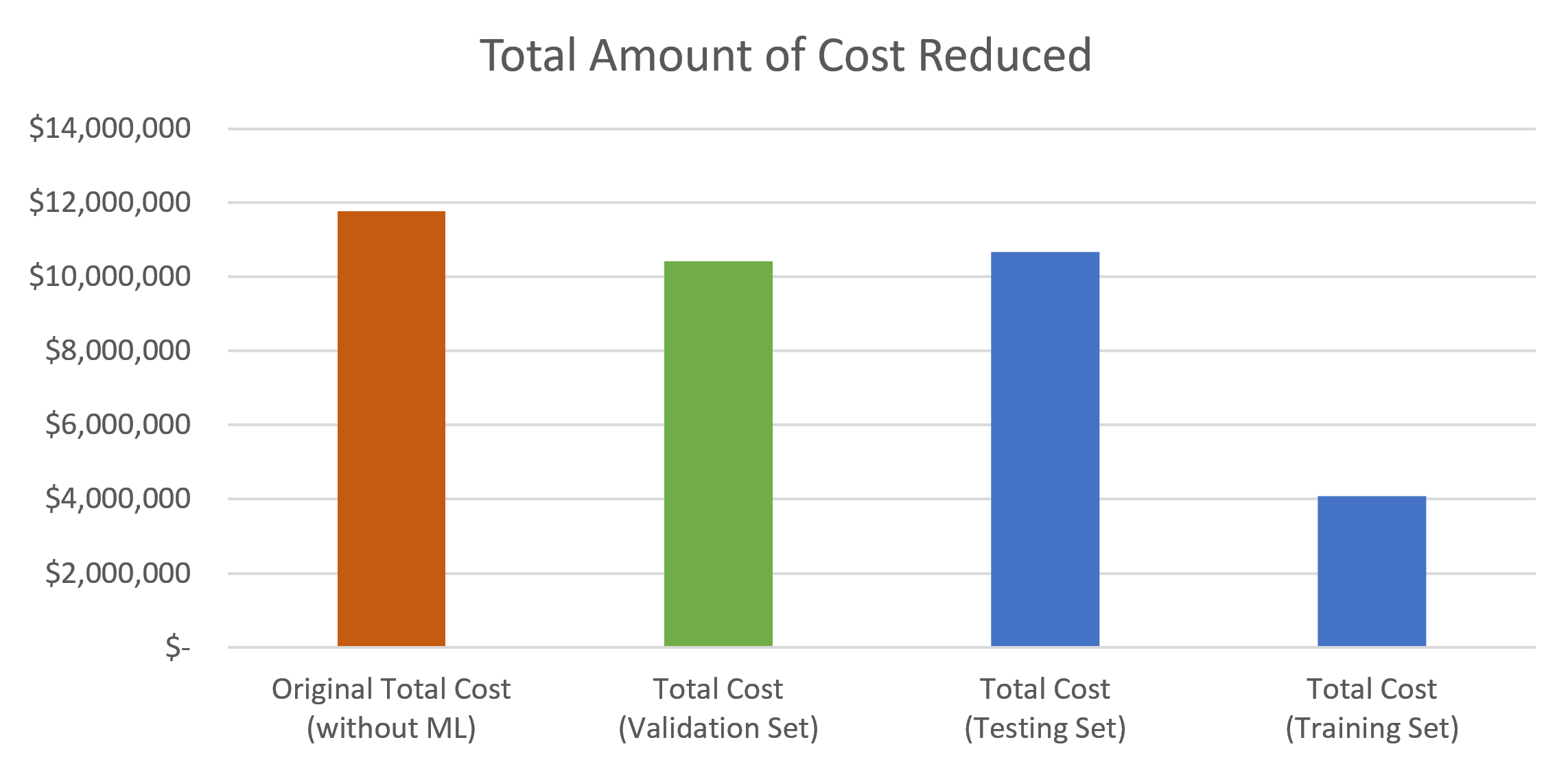

Chart #1 (Left) and Table #2 (Above): The financial impact of implementing machine learning (ML) for predictive maintenance. By incorporating ML, the maintenance cost per incident was reduced from $27,948 to as low as $9,678 in the training set, resulting in total savings of up to $7,691,636.32.
Results
Model Performance:
Training and Testing: The XGBoost model was trained on a balanced dataset and validated using unbalanced training and testing datasets. The model showed near-perfect accuracy on balanced data and a high level of performance on unbalanced data.
Feature Importance: Key features contributing to the model's predictions were identified.
Economic Evaluation:
Baseline Costs: Initially, the maintenance cost per machine was approximately $27,948, with the majority due to running machines to failure.
Predictive Maintenance Impact: After implementing the predictive maintenance model, the cost was reduced to about $25,087 per machine in the testing dataset and $24,380 in the validation dataset. This reduction translates to a saving of approximately $2,860 to $3,567 per machine.
Total Savings: Considering all 421 machines, the total savings amounted to approximately $1.204 million, equating to a 10% reduction in total expenses.
Confusion Matrix Analysis:
True Positives, False Positives, False Negatives, True Negatives: Defined within a 90-day forecast window with a cutoff probability of 0.02. This nuanced approach provided a more realistic view of the model's performance in predicting equipment failures.
Validation:
The model was validated against a separate dataset (df_total) to ensure its robustness and reliability in a real-world setting.
Final Words
This project is partly based on the pioneering work of Shad Griffin in the field of Machine Learning for Equipment Failure Prediction and Predictive Maintenance (PM). Shad Griffin, a Certified Thought Leader and Data Scientist at IBM, has been a significant source of inspiration and guidance in my exploration of machine learning applications in mechanical and system engineering domains. His insights and methodologies have greatly influenced my approach and understanding of these complex systems.
For more in-depth insights and related works, you can visit Shad Griffin’s blog (https://medium.com/@jshadgriffin) and explore his GitHub repository (https://github.com/shadgriffin)
Here is the original analysis by Shad Griffin: https://github.com/shadgriffin/machine_failure/blob/master/Machine%20Learning%20for%20Equipment%20Maintenance%20-%202022.ipynb